Abstract
The purpose of this paper is to present and discuss a patent-pending technique called a Data Vault™ – the next evolution in data modeling for enterprise data warehousing. This is the
fourth paper in a series of papers that will be published on a Data Vault. This paper explores the Data Vault example from Series 3 and extends the concepts of Linking, Satellites attached to Links
and various join techniques. Link tables are many-to-many instantiated relationships that appear in the business and logical models. Satellites that hang off the Link tables represent the changing
information within that context. Series 1 discussed Hubs as singular finite business keys, and Links as any composite key.
In this paper we also explore “the problem with links and relationships.” The issues are very briefly introduced, along with some of the potential solutions. The RDBMS engines have a
lot to do with the problems of links and joins; this is a mechanical algorithm that has not been tuned to address the massive volumes of data now dealt with at the business levels. Queries against
these structures are introduced here, but will not be discussed at length until a future article.
Keep this in mind as this paper is presented. Upcoming series will discuss topics such as inserting, updating, deleting, handling facts, aggregates, near real-time and batch. It is recommended you
be familiar with the Data Vault concept, and read the previous papers on www.tdan.com.
1.0 Introduction
The purpose of this paper is to present and discuss a patent-pending technique called a Data Vault™ – the next evolution in data modeling for enterprise data warehousing. The audience
of this paper should be the data modelers who wish to construct a Data Vault data model or any data warehousing / BI specialist interested in querying a Data Vault model. Here we focus exclusively
on Link tables, Satellites that are children of Link tables, along with some of the query techniques to pull data from the Links. We also discuss the granularity issues of a Link table, adding new
Hubs and how that affects the downstream scalability. The topics in this paper are as follows:
- Link Entities.
- Satellites for Link Entities
- Facts and aggregates stored in Link Structures.
- Granularity changes to Link Entities
- Join Operations utilizing Link Entities
- Summary and Conclusions.
Several of the objectives that you may learn from this paper are:
- How to model different composite keys (Link Entities)
- How to bring facts into Satellites.
- How granularity changes impact the architecture.
- What constitutes a Link entity.
- Some of the challenges faced by the Data Vault Link entities
In the Data Vault architecture composite keys always represent a relationship between two types of business keys. These keys are housed in separate Hub entities, so in order to represent the
relationship the architecture provides a many-to-many instantiated table structure. Remember, this is for a data warehousing focus and not a 3NF OLTP system – therefore the architecture has
been re-designed to meet these needs.
The only exception to this composite key rule is the load-date which is utilized as a part of the primary key of the Satellites for time stamping the information. The time entity stands alone in
the Data Vault model, as one of a few different types of tables that aren’t linked. If we were to link the time entity (calendar) to every Satellite – the model would be too challenging
to read.
Under this guise the architecture provides a many-to-many table which plays an important role in: flexibility, extensibility, alteration, and associations between business keys. The Link entity
might just be the most powerful entity within the architecture. Of course the Link entity also introduces complexity in joins at the RDBMS engine level. This can cause problems with performance of
the data warehouse in general – but not because of the architecture, but because of the RDBMS engine underneath.
2.0 Link Entities
To understand the Link entity (Link Table) is to understand the nature of relationships across business. For instance when an individual in business states “here’s an invoice
number”, most everyone across the entire business knows what this means. Of course the interpretation of what this invoice truly means to that group could differ – hence the metadata
definitions across the company. However, when the same individual states: this invoice is billed to customer X, a relationship between invoice and customer has now been established.
Both customer and invoice stand alone. In other words, an Invoice doesn’t necessitate having the customer (an invoice could be internal), and the customer could have just contacted marketing
and may not have anything to be invoiced for. Common business sense says we should link Invoices to at least one customer – then that begs the definition of Customer; is it corporation,
individual, or other?
There is another embedded theme to these statements: real-time, zero latency enterprise, near-real-time, on demand. Call it what you will. The data modeling architectures of today (save the Data
Vault) produce dependencies on data sets and arrival times across processing engines that prohibit the use of near-real time data synchronization. In the Data Vault, it’s partly because of
the Link table, and partly because of the way the Hubs are structured that allows near-real-time feeds to “late-bind” data; or synchronize the data as it arrives. Of course this is the
subject of metadata and I’ve digressed – so let’s bring it back up a level and focus on the relationship between the elements.
The definition that is given in Series 1 is as follows: “The Link represents the relationship or transaction between two or more business components (two or more business keys).” A Link
entity might appear as follows:
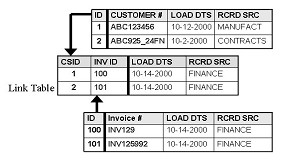
This indicates only two layers of granularity: customer by invoice. To add layers of granularity, add other Hub keys or other Link keys. The above figure shows that customer 1 is linked to invoice
100, and customer 2 is linked to invoice 101. Of course the top and bottom tables are Customer Hub and Invoice Hub respectively.
Ok, so what about the 1 to 1 or 1 to many, or many to 1?
This is now left to be handled by the loading process that’s populating the structures appropriately. There are a couple main reasons why we implement a Link structure regardless of the
relationship:
a) Future extensibility – we can easily add Hubs with additional Links to our existing Data Warehouse model without disturbing existing history. This is critical to the success of
the model going forward. Particularly when business requirements are changing rapidly today – the data systems and data models must be able to keep up. In the future, this architecture may
play a role in dynamically extensible data models at the physical level.
b) Business Rule Changes – today the rule may be 1 to 1, in the future the business may dictate that in fact, 1 customer can be linked to more than 1 Invoice, or maybe 1 invoice can
be sent to M customers. When the business changes; this structure keeps the model clean and allows history to be preserved while the new rules are put in place.
c) Misplaced Data – Too frequently in existing data modeling architectures there is data associated with tables that have composite keys – but doesn’t belong there. In
this modeling architecture it becomes easier to spot modeling errors and correct them – in other words put the data where it belongs, directly with the related key.
d) Granularity Control – keeping the granularity of information together is important. Making sure that the information or data elements are placed where they belong, and that the
aggregations are controlled by the granularity of the key. Adding another key to a Link entity is very similar to adding another dimension to a fact table. It can change the granularity of the
satellites associated with the Link. For Links without Satellites it becomes very easy to make the changes.
Why build a link table in the first place?
Parts of this question were addressed in series 1 of these articles. It is important to recognize that items exist in our physical world without attribution to other items. Cars exist without
drivers, cans of soda exist without consumers, pants exist without wearers. These items are all tagged, numbered, and identified in some fashion. When an individual becomes a consumer or owner or
wearer they can now be associated with these items. This is vital in increasing the level of understanding of the information we have at our fingertips. Without associations of information we have
a great deal of trouble recognizing the patterns and the reasons for those patterns to exist.
The associations can be drawn from primary and foreign keys, but why separate it into link tables?
For the most part the business is interested in not just the association, but the patterns and orientations of the association itself. By separating the associative data we can begin to run
inference engines against these patterns and learn new facts we may have missed before. The primary reason is flexibility. Associations change over time. Once I’ve consumed a can of soda, I
discard the can for recycling – now the recycler is the owner of the can, not me. If history of this relationship can be tracked, then future relationships may be guided in some fashion
through incentives. This is commonly known as the use of data mining to find inferences and associative patterns, segmentation and deterministic patterns hidden within the data that we might miss
or never find unless drawn out. Note: RFID (radio frequency identifier tags) are Nano technology based items which allow tracking at the chemical level of any manufactured item.
Once put into a link table these associative patterns are easier to spot, the flexibility of architectural change in the future is easy to execute in the data model, and exploratory relationships
can be created, scored and destroyed at will (mechanically). There will be more on the data mining to Data Vault applicability in a later article.
2.1 Satellites for Link Entities
Great, what about duplicate keys during a load process?
The next issue we may deal with (generically across all these styles of end-dates) surrounds the loading of duplicates during a single streaming load or batch load; where duplicates (by key, deltas
by row content) arrive within the same fraction of a second; due to the rapid loading speeds of bulk-loading processes.
Duplicate keys should only ever appear within the Satellite and PIT tables. Duplicate keys should never be seen by a Hub or a Link. These two structures should contain one and only one copy of the
surrogate and business keys that they represent. The Satellites are where the problem resides, and with the PIT table being a satellite derivative it presents a similar issue. The problematic rows
may look as follows:
SOURCE:

Where row 1 is the first from an audit trail on the source system, and row 2 is an update on the source system. In this case they are both inserts into the satellite. There
1) Add an incremental column – this adds data and width of the table
2) Add seconds to the time stamp – requires complex logic to manage, changes the time stamping process
3) Re-sort the rows into two sets of processing – one for inserts (original), one for insert/update comparisons.
4) Pre-generate the load-date into the staging area; add one second, or one minute to the information to allow it to pass into the target table.
All of these are potential solutions. The only solution that appears to work frequently and consistently for near real time is solution 1. Alternative solutions are currently being explored and
will be discussed at length on www.danlinstedt.com (the home of the Data Vault). If a strategic data warehouse is being built (meaning data latency is not
an issue), then staging the data and usually pre-processing the load date is a great solution. Once the data is loaded into a staging area it can be partitioned, controlled, and updated in a
parallel fashion. What works to our advantage here is that usually the case mentioned above is less than 10% of the total data volume. This helps keep the work of the updates down, and the
performance up.
If a tactical (active/near-real time) data warehouse is being built then a more complex transaction check process must be built – the real question now becomes: why do we receive two of the
exact same rows in the same millisecond? If it’s a near real time system, this could be considered a duplicate transaction, and literally only inserted once – and a message should be
sent to the administrator alerting them that there may be a problem in the “processing” of the source system rows. Otherwise, these transactions should be at least (if not more) than
one second apart.
Satellites function as a historical store for all history. The satellites on the Link entities represent a history of the relationship that is bound by the composite keys. Additional discussion on
Satellites will ensue in a follow-on paper.
2.2 Facts and Aggregates in the Link Tables
One of the questions that has been asked recently is the ability to handle aggregations or pre-built aggregates within a Data Vault. The answers are interesting to say the least. There are two
emerging theories here: 1) that a new satellite can be attached as a child to the link table. This satellite will contain the aggregations of the detail data, and of course 2) that a new Data Vault
layer be built at a higher level of granularity. It appears as though #2 is more popular, as it allows additional de-normalization of some of the DV structures (allowing the link to look more like
a factless-fact with additional keys) and the Satellite to look like a history of aggregations…
Please don’t confuse this with a snow-flaked Star Schema. It’s not. First off the link table will contain surrogate keys that will never change (as will the Satellite), second, the
satellite can contain a history of aggregated facts – depending on how the fact table was constructed, may or may not be available.
The concept is evolving and method number 2 is currently being preferred by those implementing 1 TB Data Vaults and over. This brings us to the granularity levels of discussion.
2.3 Granularity Changes to Link Tables
Granularity is a huge question across the data marts of today. Most granularities have been “given up” due to storage, overwhelming data volumes or the simple fact of query coverage.
There’s a misconception out there that data marts can easily be rebuilt from aggregate level facts. This couldn’t be further from the truth. What if an aggregated fact has been computed
incorrectly for the past 2 years, and the granular data has been “lost” or not stored? Well, it becomes a nearly insurmountable task to over to rebuild not only the original aggregate,
but all the other aggregates which were built in turn from the aggregated data in question – not to mention “recovering” parts of an aggregate that are damaged.
What about OLTP in a warehouse (3rd normal form)? This poses other problems. The main culprit is cascading primary key issues, which in turn cause scalability and flexibility. It becomes nearly
impossible to include aggregation as an option on the 3NF model and accurately account for and define the facts that may be contained within. The Data Vault has its share of issues (such as being
currently defined as a methodology), however it is clear that it can handle granularity changes.
So where are the issues I want to watch for?
One of the places and specifically the only place is the Link table. All granularity changes are focused on the Links and any other Links that are joined together (Link to Link). Any time a primary
key is added or removed from the Link table, the definition of granularity of the satellites change. Any time the key structure (composite key) is changed, the Link table itself represents a
different set of information. However there is a very important difference between the Data Vault, 3rd normal form and Star Schema: the Data Vault Link table does not change its primary key;
especially if a surrogate is used as the link table primary key.
What does a granularity/key change mean to a Link entity?
It changes the definition of what the satellite represents. For example: in an original link table suppose I have invoice number and customer number as business keys. Three months later I add
location as a business key. Originally the satellites on this link table represented only the relationship between customer and invoice. Now, by adding location – what is stated is that the
Satellite information now represents the relationship between invoice, customer and location. The granularity of the data has just been driven one level lower.
Be aware that the change to the granularity of the key can affect the meaning of the data held within. The only place where the key changes ripple down in the architecture is here. If a Link table
is a parent (exports its surrogate key to a child link) – then the business key / granularity change will affect the meaning of the dependent child link. The good news is the best practice
that’s currently evolving is usually no more than two link tables are hooked together (except in a web-log model).
Do not confuse the change in granularity with a change in structure. If surrogate keys are utilized in Link entities, the surrogates will continue to stand without changes. The difference is in
what the data represents. Do link tables introduce lots of join logic in the RDBMS engine underneath? What happens in volume situations? How do we handle the different components of joining data
together?
2.4 Join Operations – Issues, Concerns and Mitigation Strategies
Links provide the modeling paradigm with huge flexibility and tremendous Referential Integrity. The author feels it only fair to now discuss some of the downsides (well-known) issues with links in
this technique. At first glance one would think that all these joins, or the architecture that produces these joins is at fault (or the cause of the problem). However looking deeper we discover
that this is not the case at all. Architectures should not be compromised due to technology or implementation problems in the engine layers. At the very lowest level (Data Vault or not), we begin
to discover that database engines have always had trouble with join technology. There are a few RDBMS engines that play well with this technology (but they are highly parallel, and high-cost).
The point is this: architectures should not need to be adapted to meet the short-comings of the database engines. This is where most of the database vendors fall down on the job (so to speak). The
one issue with the constant many-to-many structures in this light is the heavy introduction and use of joins at the database level.
Many of today’s relational database engines (except a couple) have trouble with joining information across table structures. Regardless of load, the joins are the single largest performance
problem in the SQL tuning world and in the database layout/construction. Indexes are not always enough to solve the join problems. In 3rd Normal form, attempting to join two 150 million row tables
by primary key can cause serious performance issues. In all honesty it is a function of how the algorithms in the RDBMS engines work to perform the join; it is not necessarily a function of the
architecture.
To alleviate the problem – the Star Schema modeling technique is purported to carry relatively small numbers of rows in the dimensions, while housing large numbers of rows in the fact tables.
This is a fallacy today – as most data marts and data warehouses have grown (in data set size) beyond original specifications. A data mart that consists (on average) of 15 million row
customer dimension can have trouble on a small machine in simply joining and aggregating fact tables at 50 million rows. So to solve this problem, a few additional physical tables are created
– aggregates. Taking data from daily to monthly level for example, may be one way to solve this problem. Another potential solution is to partition the tables, and that leads to maintenance
nightmares, loading problems, and difficulties in constructing new star schemas for additional user bases.
The problem of the join still remains, only now the architecture is adapted to overcome the weaknesses of the RDBMS engine underneath. In a perfect world of linear scalability would be handled by
the hardware and RDBMS engine. A view (select statement) against the daily data and aggregating it to monthly levels should be enough. If we examine this problem in the Data Vault it’s only
exacerbated. Here we have one possible optimal solution for granular data storage, data affinity, and flexibility that contains many to many join tables. At this point we must put pressure on the
RDBMS vendors to fix their engines to be more efficient with the source of the problem: the join in the SQL engine.
So what is the solution to the Data Vault?
Today’s “work-around” or compromise is not to compromise the architecture, but rather to add to it. Star Schemas built from the Data Vault data warehouse is one way to handle
these issues. Pre-aggregating the data, and physically splitting it up by usage pattern (by user group) would assist in dividing the work load as well as setting up additional denormalized
structures (known as collections on the Inner Core: www.coreintegration.com – Library->Data warehousing). The other option is to buy a highly
parallel RDBMS engine and utilize views against the Data Vault to get the data out. This proves extremely effective in answering the performance questions. The joins should not be compromised.
Another possibility is to eliminate the surrogate keys as primary keys, and utilize the actual business keys throughout the model. This can pose other issues to “wide-indexes” and wide
data problems. However the principle is the same. There is a system that is currently in use today (constructed over 5 years ago) with business keys and parts of a Data Vault that contains business
keys as its primary key source. It’s fast, efficient, and can join a million rows to a million rows across current satellite images in less than 45 minutes. One of the issues that is
frequently discussed is volume. The axiom? Volume changes everything, as does near real-time (less than 10 second latency).
In teaching VLDW (very large data warehouses) at TDWI (the data warehouse institute), and in discussions regarding near-real-time data stores at huge volumes, there is one fact standing clear: at
around 10 Terabytes (except in specific RDBMS engines), the world of architecture changes, referential integrity MUST be turned off, and joins are a fallacy. Its’ also well known that
streaming data at high volumes forces the same results. In both cases the engineering teams reached the same conclusions: write their own C/C++ code to handle the join functionality and set
operations. Yes – set operations, compression, and grouping appear to be the answers that all of these cases have demonstrated.
There are a few engineering teams utilizing a highly denormalized table structure (not what we are used to). It’s a special table structure built for NORA (non obvious relationship
associations by SRD – Software Research and Development in Las Vegas, NV). They utilize in-database processes, and single large table structures to relate information and establish
relationships across data with in-memory joins.
Another potential solution to overcome the join problems (until the RBMS vendors fix them) in the Data Vault is to layer the architecture. By layered, what is discussed is a similar approach to the
aggregation of data marts. The ground layer of the Data Vault will be the granular store, the first layer above that will take it to a “set operation level” of daily, weekly, monthly
– time based type of aggregation. Queries against the set operations begin to pinpoint row-counts and specific tables in which this information resides. This is an adaptation of the Data
Vault (which I disagree with) that is necessary to overcome the mechanical problems within the RDBMS engines. Of course, the other alternative is to remove all link tables entirely and write the
linking process outside the database using patent-protected algorithms that are highly scalable.
3.0 Summary
In summary, this article covers an introductory look at the Link tables; their issues, constraints, and architectural reasons for their existence. Link tables are a part of what makes the Data
Vault methodology so powerful, scalable and flexible. It exists for a purpose and will continue to serve that purpose. It also causes RDBMS heartache because the optimizers haven’t been
focused on solving large-scale join problems (most engines anyway). A good DBA can always partition, parallelize and increase the performance of join criteria within the RDBMS engines. The point
here is don’t sacrifice the architecture (remove the Link Tables) just to overcome the problems at the database level. We do however advocate the use of multi-layered Data Vaults at different
granularities which introduces the concepts of a scale-free architecture.
Keeping in mind that Link entities represent relationships between business keys. These entities are flexible and can be altered (by key) which changes the meaning of the Link and its’
surrounding Satellites. There are several Data Vault projects under-way, and one major implementation that is completed.
The next series will explore some of the query techniques needed to retrieve data from the Data Vault structures.
There is a new home for the Data Vault: www.danlinstedt.com
It is a paid-support community, where you will gain access directly to Dan for a yearly fee. You’ll gain access to the latest specifications, tips and tricks, FAQ’s, and a community
of others who are using this technology. You’ll also have access to the automated Data Vault wizard process that can create base-line data vaults for you on the fly. Customer case studies are
welcome. Corporate sponsorships of employees are encouraged.
